[CS224W] 7. Graph Neural Networks 2: Design Space

GNN 에서 computation graph, 신경망의 구조를 결정하는 것은 node's neighborhood 이다.
그림은 GraphSAGE 논문에서 가져온것으로 depth k 에 따라의 message passing임.
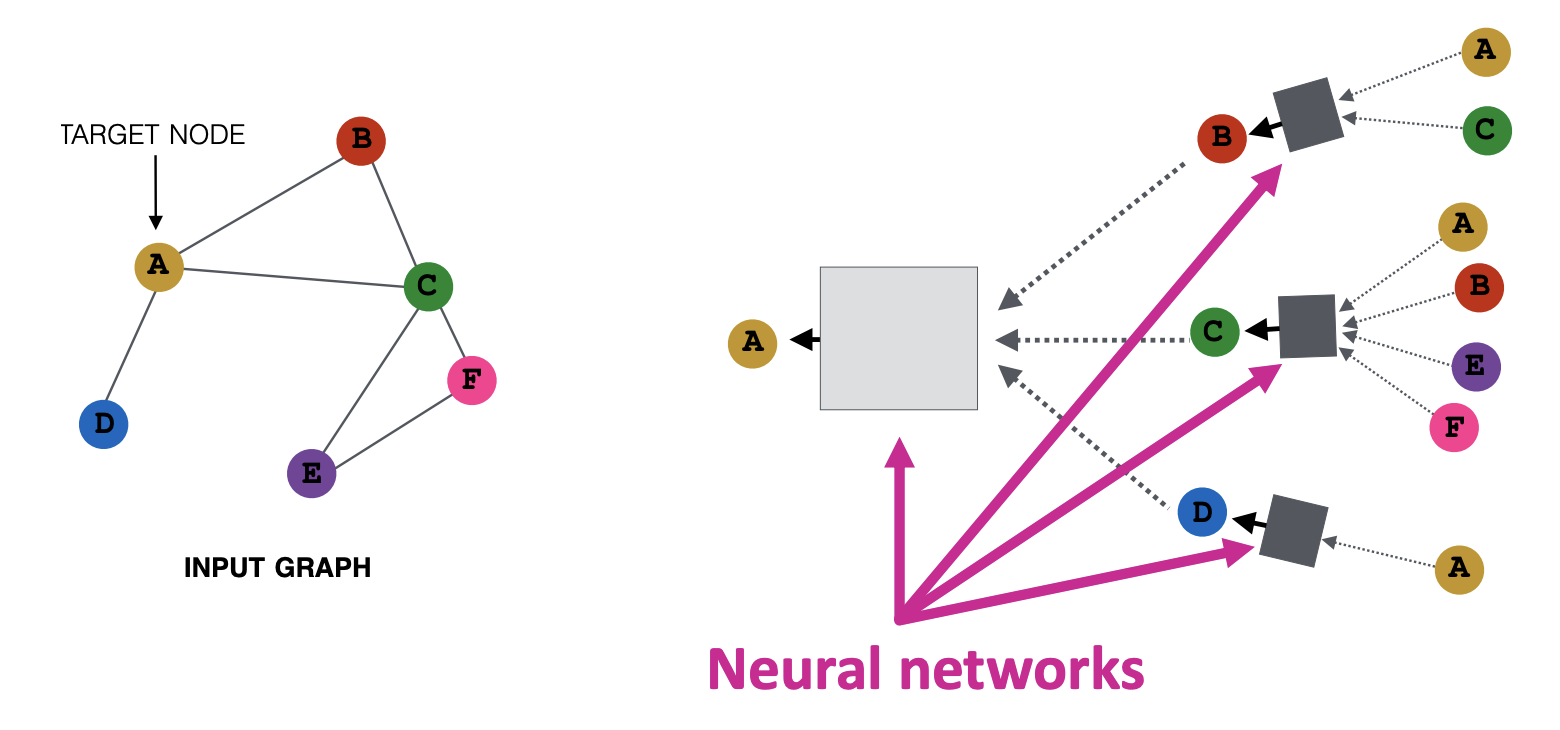
왼쪽의 그래프가 input graph 라고 해보자. A가 구하려는 타겟 노드라면 A는 그와 연결된 주변 이웃 노드의 임베딩을 aggregate 하여 결정되는데, 주변 이웃들도 그들의 이웃, A로부터 1-hop 이상인 노드로 부터 영향을 받는다. 결국 모든 노드들이 레이어마다 각자의 representation 을 가지고 있고 레이어가 깊어지면서 update된다는 컨셉이다. k=0 일 때는 node feature 를 사용한다.
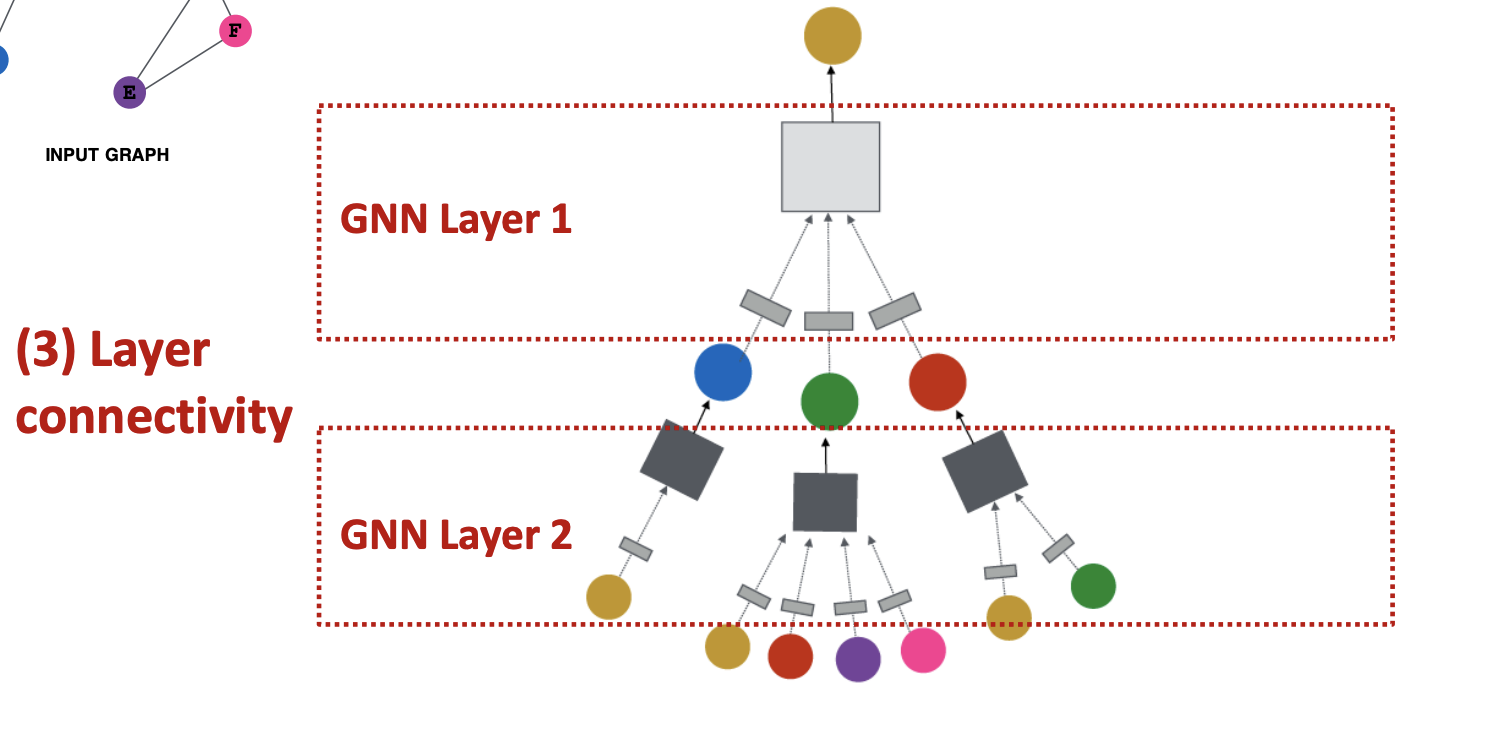
결국 GCN,GraphSAGE,GAT 건 간에 Layer 1에서는 모델마다 operation 이 다르긴 하지만 다음의 two-step process 를 거친다.
1) message transformation

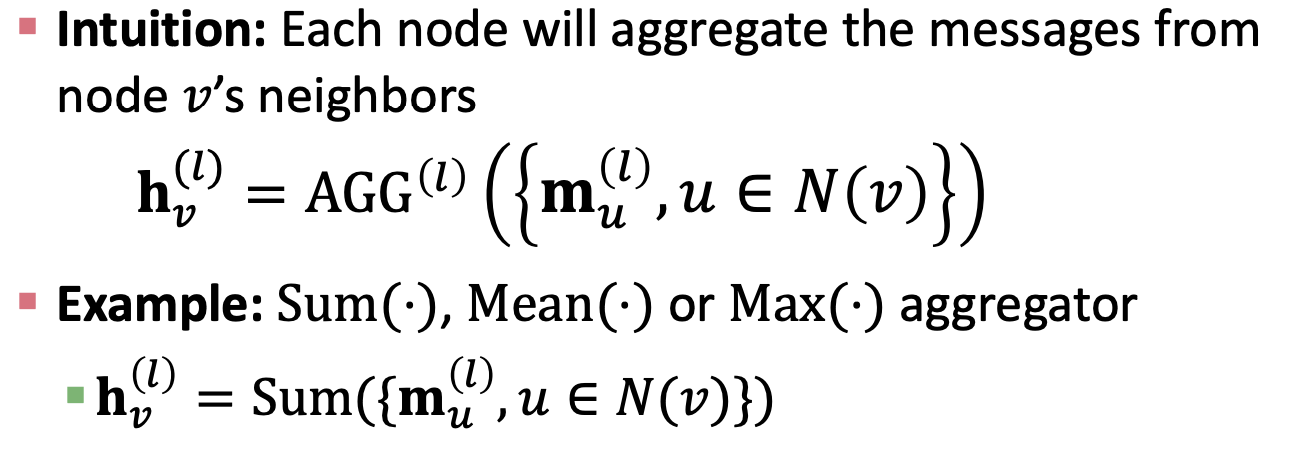
Message function 의 기본 컨셉은 이전 노드를 다음 레이어의 노드로 업데이트 시켜주는 것이다. 이전 레이어의 노드 u 의 임베딩이 weight matrix 와 곱해지는 형태는 linear transformation 으로 볼 수 있다.
오른쪽 그림의 Aggregation 은 이웃 노드들로 부터 오는 정보를 어떻게 이용할 것이냐에 대한 것이다. Sum, Mean, Max 등..

여기서 주의해야 할 점이 이대로 주변 노드들의 정보만 계속 업데이트 하다보면 노드 v 자신에 대한 정보가 update 되지 않는다는 거다. 이를 해결하기 위해 self-roop 를 만드는식으로 자기자신 노드의 정보를 다음 레이어에 보내는데, (1)message transformation 을 보면 이웃노드들은 linear transformation 후 Aggregate 함수를 거쳐서 $m^{(l)}_{u}$ 가 되고 , 노드 $h_{v}^{l-1}$ 는 다른 연산을 거쳐서 두 벡터를 concatenate 한다. 그 후엔 비선형함수인 ReLU 를 거쳐서 expressiveness 를 주면서 임베딩을 구한다.
이제 message transformation 그리고 aggregation 의 operation 으로 GCN 과 GraphSAGE 를 살펴보자.
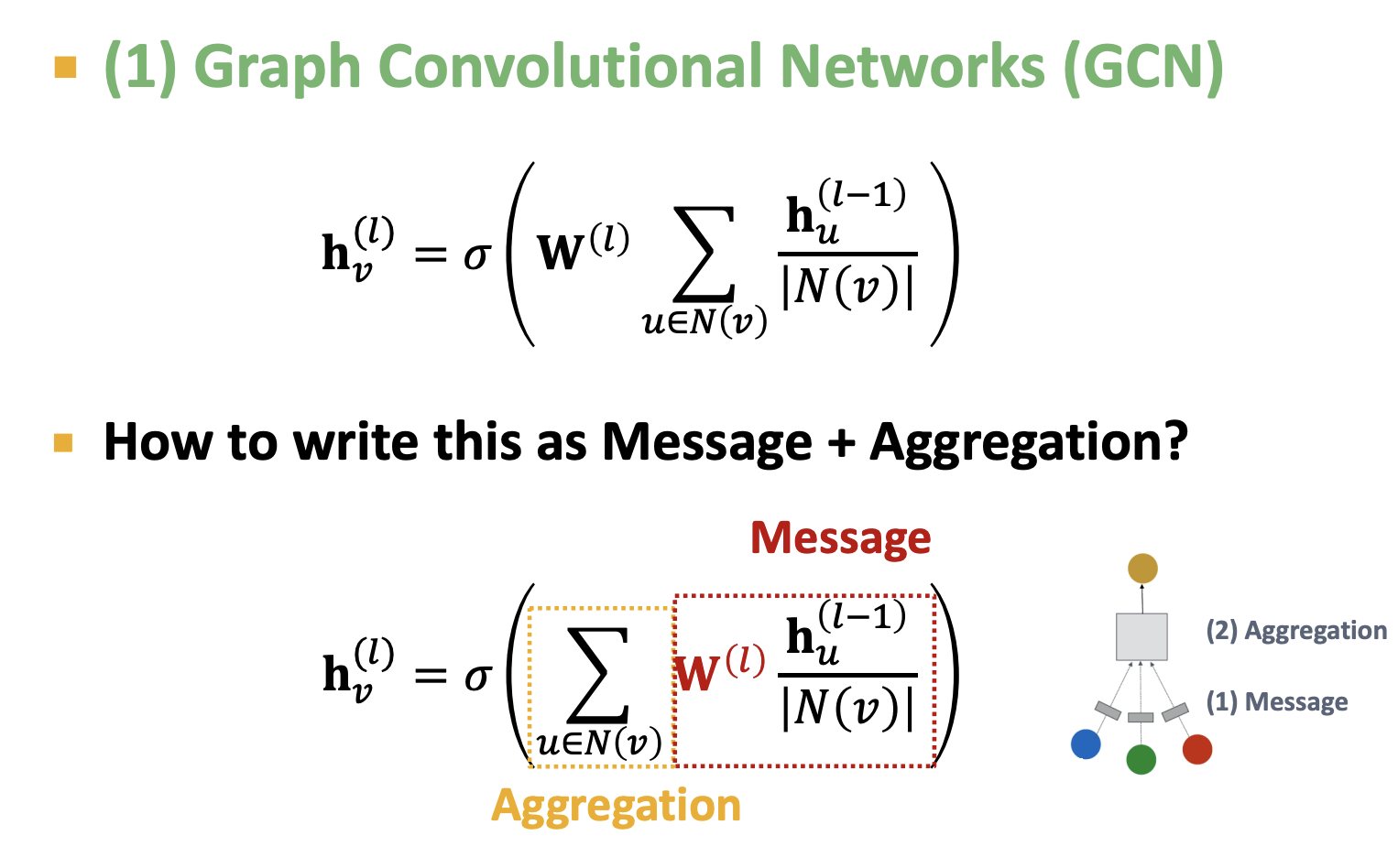
노드 v를 주변 노드들인 u에 대한 spectral convolution 연산을 통해서 구하는데, $W^(l)$과 노드 $h_u^{(l-1)}$ 의 선형변환 부분인 message transforamtion, 그리고 계산한 이웃노드들에 대한 정보를 합쳐주는 Aggregation 파트로 나눌 수 있다. 강의에서는 N(v) 로 정규화하는 부분을 normalization of node-degree 라고 하면서 넘어가지만 , 이부분이 laplacian eigendecomposition 으로 보이고 논문에서보면 여기서 각각의 D와 A에 $I_N$ 을 더해주기 때문에 자신을 더하는 부분은 생략된 것 같다.

GraphSAGE 는 위에서 계속 했듯이 주변 노드들의 message transformation vector와 이전 레이어의 노드를 Concat하여 업데이트 되게 된다. GCN 은 전체 matrix의 degree를 알아야 해서 transductive learning 이었다면, GraphSAGE는 주변 이웃들을 sampling 해서 특정 K depth로 aggregate하기 때문에 inductive learning 이다. 논문에서는 aggregate 함수로 Mean , Pool , LSTM 등의 방법들을 사용한다. 각각의 레이어마다 L2 정규화를 해주는데 각각의 벡터 스케일을 같은 스케일로 맞춰준다고 한다.

세 번째는 Graph Attention Network(GAT) 에 대해서 얘기한다. 아직 논문을 못 읽은 상태지만 별다를 건 없고 attention score를 이용해서 노드 weight 를 업데이트한다는 것 같다. $a_{vu}$는 노드v와 u의 attention weight고 각각의 노드끼리 스코어를 구하고 소프트맥스 함수로 산출하는 듯 하다.
Inductive capacbility로 GCN처럼 global graph structure를 보는 게 아니라 비용면에서도 효율적이면서 노드간의 attention 을 구함으로서 덜 중요한 노드에 대한 비중이 SAGE 보다 localized가 잘 된다는 듯 하다.

마지막으로 GNN 에도 적용할 수 있는 딥러닝 기법들을 간단하게 얘기하는데 BatchNormalization , Dropout 등이 있고 뭐 기존 딥러닝에서 쓰던이유랑 같기 때문에 슬라이드는 생략합니다.
'Graph' 카테고리의 다른 글
| 06. Structural properties of Network (0) | 2022.06.04 |
|---|---|
| 05. Node centrality rating on Networks (0) | 2022.06.01 |
| Graph Convolutional Network (GCN) (0) | 2022.02.22 |
| [CS224W] 5. Label Propagation for Node Classification (0) | 2022.02.08 |
| [CS224W] 3. Node embedding (0) | 2022.02.02 |