YOLO v1 리뷰
You Only Look Once: Unified, Real-Time Object Detection (2016)
1. Introduction
앞서 리뷰한 2 stage detection 모델들에 이어서 object detection 분야에서 획기적이었던 YOLO 모델의 첫 번째 페이퍼를 리뷰해보려고 합니다. 먼저 논문의 Abstract를 살펴봅시다.
A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance.
기존의 R-CNN에서는 region proposal과 classification을 거친 2-stage detection이였다면, 이를 보완하여 단일 네트워크 하에서 end-to-end 학습이 가능하게하였습니다. 또한 selective search를 통해 ROI를 구하는 것 대신에 full image가 들어간다고 합니다.
- 기존의 RCNN은 잠재적인 boundng box를 찾아내는 방법인 region proposal과 예측된 BB에 대한 분류기를 학습하는 두 단계로 나눠져있는데, 학습시간이 오래걸리며 최적화가 힘들다는 단점이 있습니다. 그렇지만 YOLO는 이를 단일화시켜 기존 모델보다 빠릅니다. 즉 batch processing이 없습니다.
- 모델에 전체 이미지가 들어가기 때문에 문맥적인 클래스 정보까지 인코딩됩니다. 따라서 기존모델에서 background patch를 놓치는 문제를 해결했습니다.
- generalizable representation이 가능합니다.
2. Unified Detection

일단 input image를 S X S grid로 나눕니다. 나눠진 격자 하에서 BB box와 박스들의 confidence score가 결정되는데 수식은 다음과 같다.
$$Pr(Object)* IOU^{truth}_{pred}$$
따라서 격자 안에 물체가 없으면 점수 자체는 0이 나옵니다. 각각의 BB는 5개의 값을 지니는데, x좌표와 y좌표, width와 height, 그리고 Confidence Score(Score)수치입니다. 자세한 내용은 아래서 설명하겠습니다.
참고로 논문에서는 S = 7, B = 2, C = 20을 사용하였다.
- x,y : grid cell의 정중앙을 기준으로 BB가 어느쪽에 위치하느냐에 관한 상대값입니다

- w,h : predicted relative to the whole image로 전체 이미지 대비 BB의 상대적 크기입니다
- Confidence level : object가 있을 확률 * object의 IOU
- PR(object)는 object를 잘 인식하고 있는지에 관한 것으로 배경만 있다면 0이 됩니다. IOU는 학습 데이터의 ground truth BB와 pred BB의 intersection Union을 구하는 식이다.
- Class probablity(C) : 앞의 confidence값을 이용하여 BB가 배경이 아닌 object 를 포함하고 있을 때 각 클래스별 조건부확률을 구할 수 있습니다.$$**PR(Class_i|Object)PR(Object)IOU = Pr(Class_i)|IOU$$
이를 통해 각각의 바운딩 박스마다 class-specific한 confidence score를 계산할 수 있으며 이 값은 밑의 두가지 특징을 인코딩합니다.- box 안에 특정 class가 등장할 확률
- bounding box 가 object를 얼마나 fit하게 잡는지 여부
최종적으로 예측하는 값은 (S X S X (B*5 + C)) 이기 때문에 7 X 7 X 30 tensor 이 됩니다.
이를 통해 기존 2-stage model이 region proposal과 classification 을 나눠서 함으로써 발생했던 문제들을
class-specific한 score를 구하는방식으로 unify함으로써 해결했다고 볼 수 있습니다.
3. Network Design

YOLO는 24개의 Convolutional layer과 2개의 FC layer 의 구조를 사용합니다.
주황색 프레임은 pretrained Network인 GoogleNet으로 20개의 CV layer를 사용하였고, 결과적으로 top-5 acc가 88%가 나왔다고 합니다.
여기서 눈여겨볼점은 기존 ImageNet 데이터셋 크기가 224x224였는데 scale factor를 2로잡아 인풋 이미지가 448x448x 3이라는점입니다.
논문에서는 "Detection often requires fine-grained visual information so we increase the input resolution of the network"라고 하며 , 경계선이 흐릿한 이미지에서 학습이 더 잘 됐다는 해석이 있습니다.
4. Training
Training Network에서는 추가적으로 4xConv 층과 FC layer를 거쳐서 최종적으로 1470의 Tensor 가 출력됩니다. (7x7x30) 여기서 dataset의 class 개수는 20(C)입니다.
- x , y , w , h 를 normalize하여 0~1사이의 값으로 바꿨다.
- Activation function으로는 leaky rectified linear activation (LReLu)를 사용하였다.
- 최적화에 있어서는 SSE 사용 (Sum-squared error)하였다.⇒ 이를 loss function 의 정의를 통해 해결하였다.
- 사실 이 방법이 localization, classifiaction 에러의 가중치를 똑같이 잡기 때문에 이상적이진 않다. 또 object가 없을 때 C score는 0이 되는 셀들이 많으므로, "overpowering gradient" 문제도 있다.
- Loss function

-
- $\lambda_{coord}$ 는 객체가 존재할 때의 값으로 5 , $\lambda_{noobj}$ 는 그렇지 않을 경우로 0.5값을 가진다. $S^2$은 grid의 수이므로 행렬이니 제곱인 49가 될것이다. B는 $S_i$ 셀의 bb이며 총 개수는 98가 됩니다.
- i 번째 셀의 j 번째 박스만을 학습하겠다는 뜻이다. 모든 셀의 bb에 대해서 학습하는 건 비효율적이기 때문에 각 객체마다 IOU가 가장 높은 bb에만 패널티를 주는 식으로 학습이 진행됩니다.
- 객체가 존재하지 않을경우의 가중치값은 0.5로 학습에 영향을 미치지 않게 하고
- i,j bb에 객체가 없을 때만 작동한다는 뜻입니다.
- 식을 크게봤을 때 localization과 classification 으로 나눌 수 있는데 클래스 분류에 해당하는 부분으로 앞과는 달리 패널티가 없습니다. 이는 앞서말한 localization 에러의 비중을 더 높게 해야하 문제와 대응됩니다.
- 각 셀별 클래스 분류 오차에 관한 것입니다.
5. deepresearch slide
여기까지 논문을 다 읽고도 정확한 Non-max suppresion 이 어떻게 이루어지는지 확실히 이해가 되지 않아 Deepresearch 팀에서 만든 슬라이드 자료를 첨부하였습니다.

위 그림은 앞서 설명한 전체 네트워크에 대한 구조이며 output 인 7x7x30 tensor 에 대해서 살펴보겠습니다.

$SXSX(B*5+C)$의 부분으로 grid cell당 bounding box는 2개 이기 떄문에 5*2 이고, 뒤의 20은 dataset의 class 개수입니다.

class prob.에서 $PR(Class_i|Object)*PR(Object)*IOU = Pr(Class_i)|IOU$ 라고 했는데, 그림은 bb1 score를 구하는 부분으로 PR(object)* IOU로 confidence score, 거기에 20개의 class 중 속할 확률인 PR(Class|Object) 를 multiply 하는 파트입니다.

이 과정을 each grid cell(49)당 BB(2)씩 연산하게 되므로 total BB는 다음과 같습니다.
이제 계산한 confidence score를 가지고 어떻게 classification을 할까요

20 개의 클래스 중 첫번째는 개에 대한 분류라고 하겠습니다. 기준치인 일정 threshold값 (그림에선 0.2) 가 넘는 것만 뽑아서 sort descending를 하여 0인 값들에 대해서는 NMS(non-max supression)을 합니다.

bb47 이 가장 큰 값이므로 bbox_max, 이며 그 다음값인 bb20은 bbox_cur(i) 이라고 하겠습니다. 이 때 이 둘의 IOU인 IOU(bbox_max,bbox_cur) > 0.5 이면 ⇒ bbox_cur 값은 0이 됩니다.
이 과정을 bbox_max를 제외한 모든 bbox_cur(아마 97?)에 대해서 수행하여 0.5 이상인 값들만 zero vector 로 바꿉니다.

이를 통해 0은 아니지만 크지않은 위의 분홍, 파랑 박스들 같은 inefficient한 BB들의 스코어가 0이되며 NMS의 Intition이라고 할 수 있습니다. 이 과정을 통해 target box에 해당되지 않는 많은 BB들의 스코어값이 0이 되었을 것입니다.

제가 해석한 바로는 20개의 score 중 max_index 를 가진 값을 통해 (vertical하게 봤을 때), class 를 결정하고, 그 class에 속하는 값 중 max_score가 최종 class를 대변하는 bounding box가 된다고 봤습니다. 가령 bb4와 bb82가 모두 class가 cat일 수 있고, bb82 중에서도 max score가 class_cat 이 0.5, class_dog가 0.6 이 될 수 있지 않을까(horizental) , 그 중 가장 높은 값을 최종적으로 선택한다고 이해하였습니다.
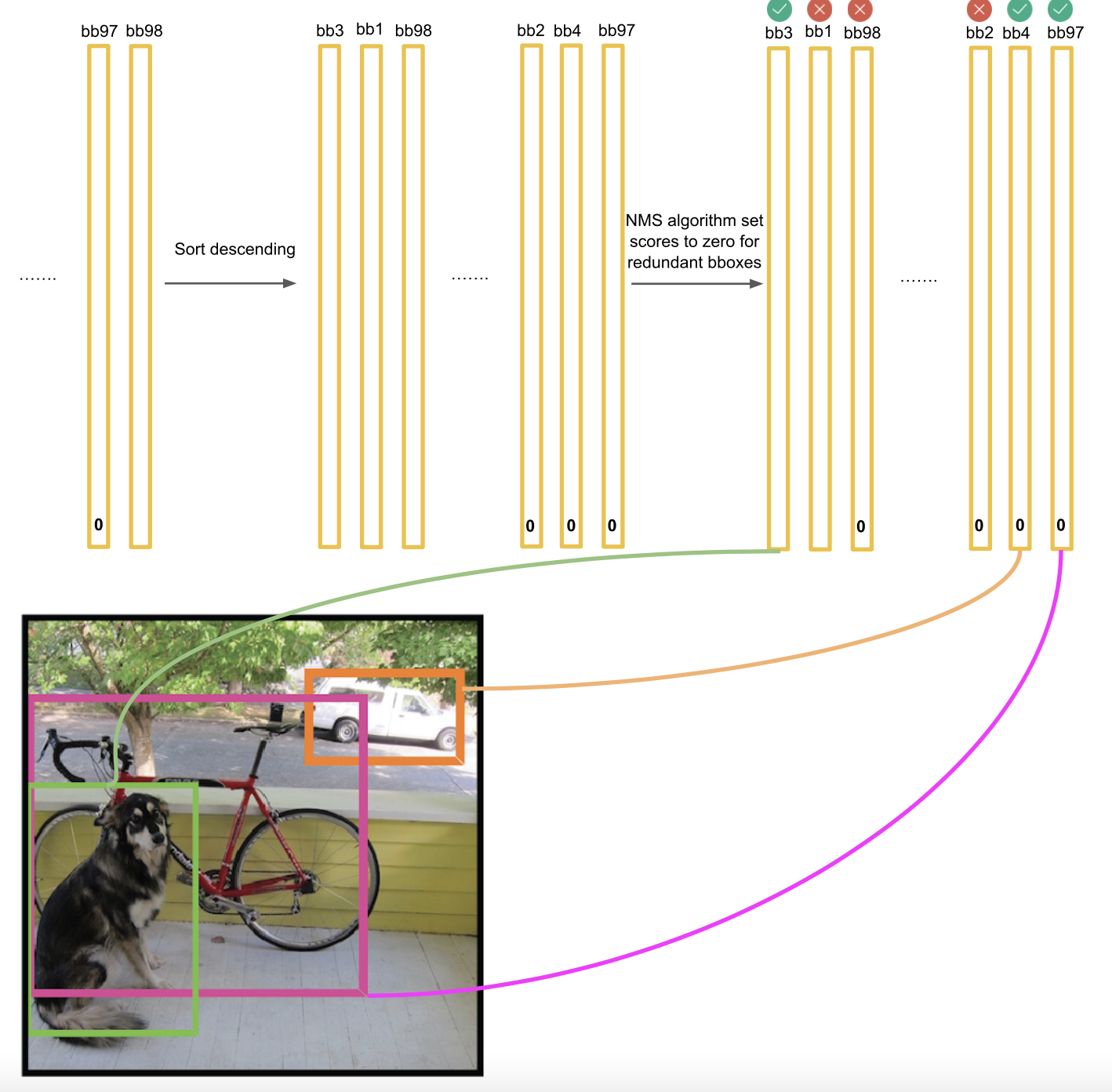
max_bbox 를 통한 최종 deteection 결과입니다.
'machine learning > Article review' 카테고리의 다른 글
| Asymmetric Loss For Multi-Label Classification 리뷰 (1) | 2021.12.20 |
|---|---|
| BERT4Rec review (0) | 2021.12.19 |
| Fast & Faster R-CNN 리뷰 (0) | 2021.12.03 |
| [R-CNN] Rich feature hierarchies for accurate object detection and semantic segmentation (0) | 2021.12.03 |
| [GoogLeNet] Going deeper with convolutions (0) | 2021.11.29 |