[GoogLeNet] Going deeper with convolutions
1. Introduction
VGGNet 이후 ILSVRC 2014에서 1등을 한 논문인 GoogLeNet 을 리뷰하려고 합니다.
2. Motivation and High Level Considerations
딥러닝 네트워크의 성능을 향상시키는 확실한 방법은 네트워크의 사이즈를 키우는 것이다.
레이어를 깊게 쌓아 depth 를 늘리거나 레이어의 유닛 수를 늘려 width를 키울 수 있지만 두 가지 문제점이 있다.
첫째는 오버피팅의 가능성이고, 두 번 째는 네트워크 사이즈에 따른 컴퓨터 리소스의 부담이다. 컨볼루션 레이어에서 필터 수는 곧 파라미터의 수이고, 깊게 쌓을수록 연산량은 배가 되기 때문이다.
그래서 어떻게 컴퓨팅 자원을 효율적으로 배분할까? 에 대한 대안으로 논문에서는 dense한 Fully connected 구조 에서 Sparsely Connected 구조로 바꿀 것을 제시한다.

Their main result states that if the probability distribution of the data-set is representable by a large, very sparse deep neural network, then the optimal network topology can be constructed layer by layer by analyzing the correlation statistics of the activations of the last layer and clustering neurons with highly correlated outputs.
모든 노드를 연결하는 dense한 방식은 컴퓨팅 리소스를 많이 쓰기 때문에 dataset의 분배 확률을 sparse하게 표현 가능하다면, 통계적 분석 이후 correlated outputs만 클러스터링하여 사용하자는 것이고 그 시도로 등장한 것이 아래의 Inception module이다.
3. Architectural Details
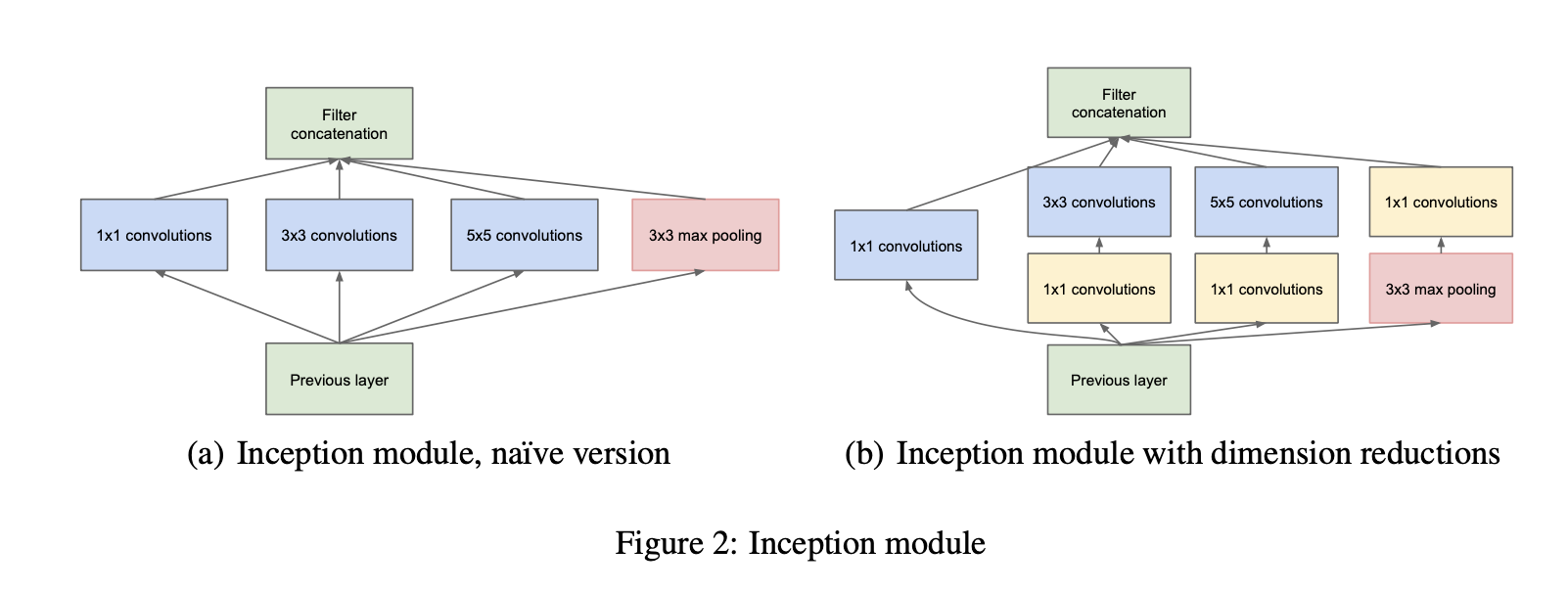
The main idea of the Inception architecture is based on finding out how an optimal local sparse structure in a convolutional vision network can be approximated and covered by readily available dense components.
- (a) naive version의 문제점 : 필터 개수가 크기 때문에 너무 expensive하다. pooling layer 의 추가로 인해 훨씬 커졌다.
- (b) dimension reduction을 해야겠다 ← 낮은 차원의 임베딩으로도 충분한 정보획득 가능하기 때문에 가능. expensive filter를 거치기 전에 1x1 convolution을 해줬다.
컴퓨팅적 효용성 뿐만 아니라, 직관적으로 봤을때 이 방법은 시각적인 정보들이 various scales(기존의 AlexNet, VGGNet 은 같은 레이어에서 동일한 사이즈의 필터 커널 사용)로 일차적으로 처리되고 다음단계에서 다른 스케일의 피쳐들을 동시에 추출한다는 점에서 의미가 있다.
상위 레이어에만 인셉션 모듈을 사용하고 그 아래에는 기존 컨볼루션 레이어를 사용했다.
4. GoogLeNet
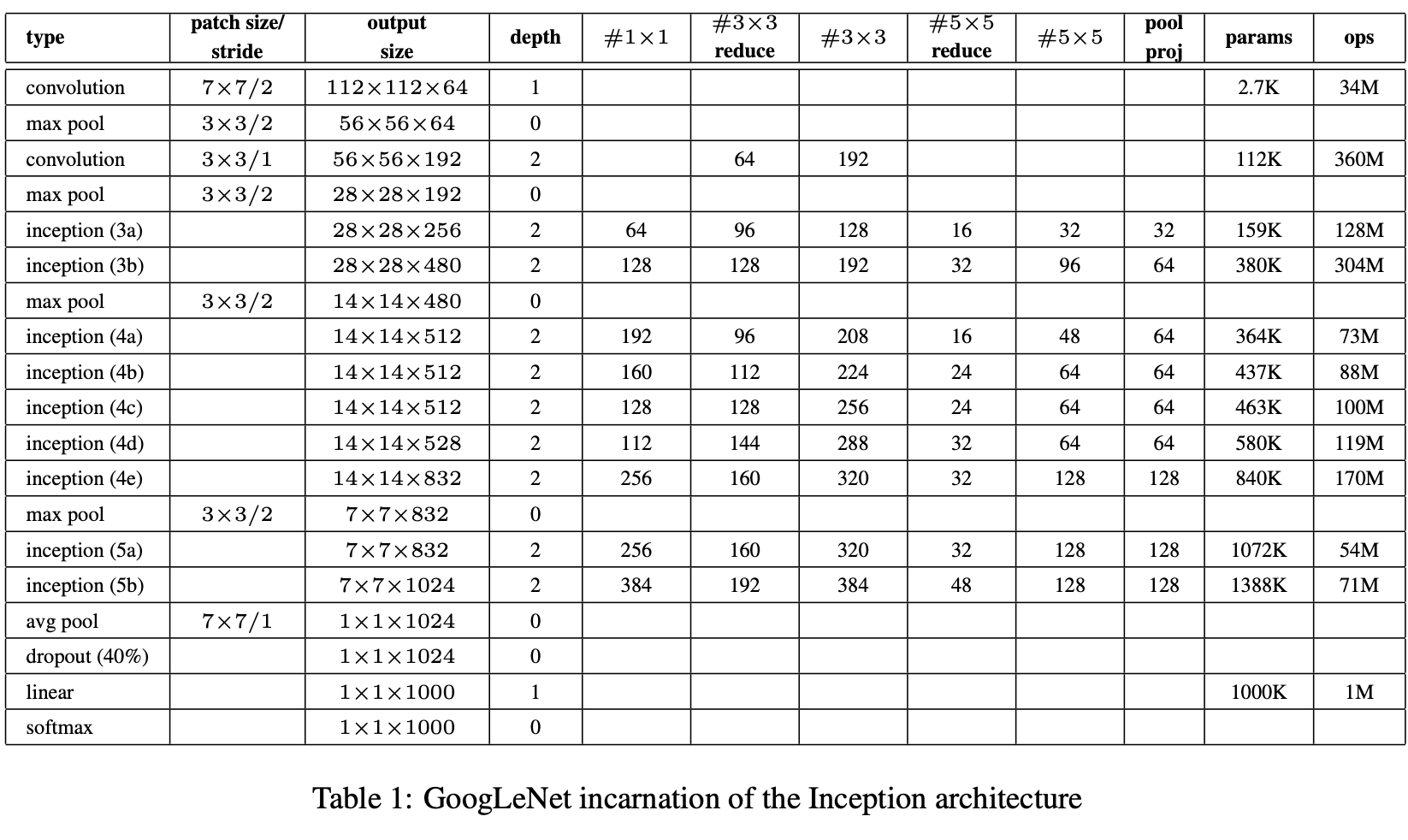

- google에서 만듬 + LeNet 네트워크 응용.
- 모든 컨볼루션에서 인셉션 모듈과 LeLU 사용.
- 224x224 receptive field
- 22개의 layer or 27(with pooling)
- fc layer 대신 average pooling 사용 → 0.6% 증가
5. global average pooling
이전의 CNN 아키텍쳐들이 네트워크 마지막에 Fully connected layer를 이용하였지만 구글넷에서는 대신 global average pooling 방식을 사용. 최종적으로 1차원벡터가 나오는 것과 동일하지만 number of features 즉, 최종 feature map의 개수를 정하고 피쳐맵의 평균값들을 벡터값으로 사용한다.
학습 가중치의 개수가 확연하게 줄어든다. fc layer 가 사라지고 평균값을 쓰니 고만큼 학습 부담이 줄어든다.

6. Conclusions
Our results seem to yield a solid evidence that approximating the expected optimal sparse structure by readily available dense building blocks is a viable method for improving neural networks for computer vision.
[참고 링크]
GoogLeNet (Going deeper with convolutions) 논문 리뷰
논문 제목 : Going deeper with convolutions 이번에는 ILSVRC 2014에서 VGGNet을 제치고 1등을 차지한 GoogLeNet을 다뤄보려 한다. 연구팀 대부분이 Google 직원이어서 아마 이름을 GoogLeNet으로 하지 않았나 싶..
phil-baek.tistory.com
'machine learning > Article review' 카테고리의 다른 글
| YOLO v1 리뷰 (0) | 2021.12.16 |
|---|---|
| Fast & Faster R-CNN 리뷰 (0) | 2021.12.03 |
| [R-CNN] Rich feature hierarchies for accurate object detection and semantic segmentation (0) | 2021.12.03 |
| [review]Similarity_Cohen Malloy Nguyen(2019)LAZY PRICES (0) | 2020.04.04 |
| [review] Large-sample evidence on firm's year over year MD&A modification (0) | 2020.04.01 |